
TL;DR
This article examines the criticized Bloom-7B language model, comparing it to newer open-weight competitors like LLaMA-7B, Falcon-7B, and Mistral-7B. It explores claims of obsolescence, addressing architectural features (e.g., Alibi embeddings and tokenizer size), training limitations (undertraining on fewer tokens), and alternative design choices in newer models (SwiGLU, RMSNorm, GQA). The findings suggest Bloom’s underperformance stems more from undertraining than outdated architecture. Despite the critiques, the article argues for the potential of open-source models like Bloom, emphasizing the need for better scaling and data strategies to unlock their competitive edge.
Bloom, the model everyone hates…
*This article was first released in French on my Substack as part of my work at CEA List in the context of the OpenLLM France project. The aim of this article is to nuance the weight of the architectural source of improvements in LLMs, compared to their compute needs and quantity of data seen
By this token, it also defends the historical choices made in Bloom—a model often denigrated—despite many of its architectural choices likely enabling competitive performance with proper data scaling.
In this rapidly evolving field, I often feel the need to distinguish between noise and genuine progress. Companies frequently showcase innovation by training their own model versions. In this article, I question the sources of performance improvements, comparing Bloom-7B with state-of-the-art models at the time, such as LLaMA-7B, Mistral-7B, and Falcon-7B. *
In a context where language models are emerging at a breathtaking pace, with enormous financial stakes for their creators and ongoing debates about the legislation surrounding their open-sourcing, it is crucial to objectively assess the differences between open-source and proprietary models. Fully open initiatives have the potential to match - and, I am convinced, surpass - the closed or semi-open efforts of the major AI players.
In this article, I examine the true sources of performance differences between Bloom- the [most transparent series of models to date](https://crfm.stanford.edu/2023/06/15/eu-ai-act.html- and its open-weight competitors, with a particular focus on the 7B version, the size currently favored in the field.
An obsolete model? 🤔
This is a recurring theme in discussions I hear among experts-whether researchers, engineers, or ML enthusiasts: any mention of this model or a project using it almost invariably elicits a visceral reaction of disdain from the interlocutor.
“We tried it in production, and the results were absolutely terrible.”
“Bloom is outdated; it’s clearly not state-of-the-art.”
While HuggingFace’s unique BigScience initiative deserves praise for its commitment to open source, open science, and open data principles, as well as its representation of 46 languages (+13 programming languages), it must be acknowledged that individual feedback and performance on academic benchmarks (despite their limitations) are underwhelming compared to models like Falcon, LLaMA, and more recently Mistral.
Despite the release of LLaMA in February 2023, some Finnish initiatives have chosen not only to continue training Bloom (Bluumi), but also to train models based on its architecture “from scratch” (e.g. Poro-34B). For many, this approach seems almost heretical.
But the real question remains: has there been significant architectural progress to justify such reactions? What really causes Bloom’s underperformance? In this post, I hope to provide some food for thought.
An “ill-conceived” model? 🤷
“Nah, but there have been a lot of architectural improvements since Bloom, like rotary embeddings, etc.”
The architecture? The data? The training method? Pre-training models is a task where the experimental nature of deep learning and its high cost make the classic “ablation study” approach impractical.
So, amidst the current craze for 7-billion-parameter models - the infamous ‘7B’ - I examined the key differences (when documented) between Bloom, Falcon, LLaMA 2, and Mistral.
| Model Name | n_layers | n_heads (per layer) | hidden_size (size embeddings) | size_kvq | intermediate_size_FFN | layer_norm | activation_function | vocab_size | tokenizer | pos_embeddings |
|---|---|---|---|---|---|---|---|---|---|---|
| Bloom-7b | 30 | 32 | 4096 | 128 | 16 384 | LayerNorm | GeLU | 250880 | Byte-level-Pair Encoding | Alibi |
| Falcon-7b | 32 | 71 | 4544 | 64 | 18 176 | LayerNorm | GeLU | 65024 | Byte-level-Pair Encoding | Rotary |
| Llama2-7b | 32 | 32 | 4096 | 128 | 11 008 | RMSNorm | SwiGLU | 32000 | Byte-level-Pair Encoding | Rotary |
| Mistral-7b | 32 | 32 (GQA 8 k_v) | 4096 | 512 | 14 336 | RMSNorm | SwiGLU | 32000 | Byte-Fallback BPE | Rotary |
Bloom and its architecture 🏗️
Architecturally, all models share a transformer-decoder design, and there are few distinctive elements that stand out to explain Bloom’s poor performance from this perspective.
In the end, it is quite comparable to the other models, except for two aspects: Alibi positional encoding and a much larger tokenizer.
Distinctive Features of Bloom
Alibi: The Root of All Evil?
Positional embeddings, Rotary (RoPE) and Alibi, are two positional encoding methods introduced in 2021. In its paper, Alibi compares itself to RoPE on extrapolation to sequences longer than those encountered during pre-training, demonstrating an “out-of-the-box” superiority in this regard:
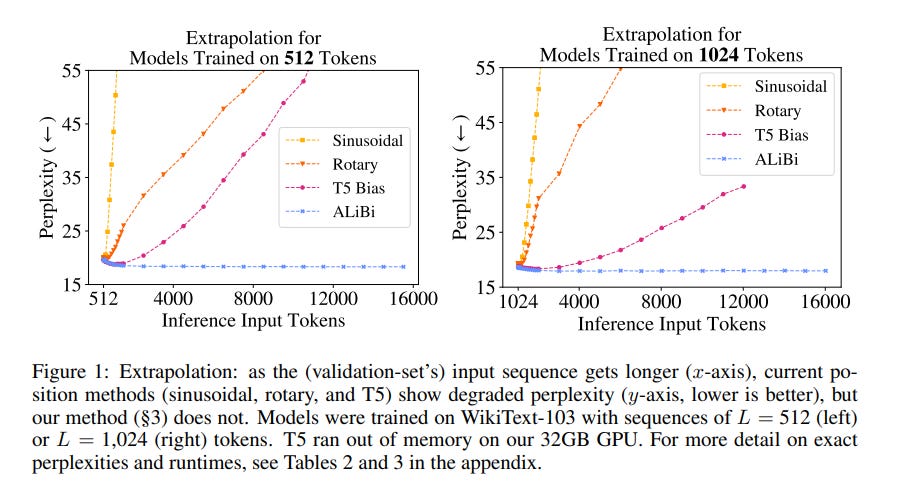
Referring to the article on the Falcon model family, whose implementation code allows the use of Alibi, we can observe the results of the experiments carried out to justify the choice of RoPE:
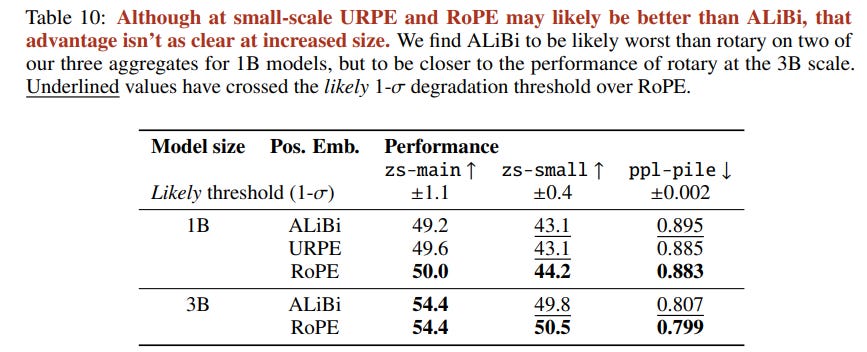
They note that the observed advantage may be significant for 1B models, it becomes less clear as model size increases.
“At the 1B scale, we find a likely advantage to using RoPE over ALiBi; however, that advantage diminishes at the 3B scale, and is insufficient to conclude clearly. One remaining advantage of ALiBi is its compute overhead: it is significantly cheaper to compute than RoPE; however, with custom Triton kernels (Section 5.3.2) we are able to mitigate that overhead.”
The team’s choice of RoPE is finalized, though the motivations are not entirely based on technical considerations:
“In-line with other popular large-scale models, we adopt rotary positionnal embeddings, and use custom kernels to mitigate the overhead.”
Ultimately, this comparative study was also conducted by Bloom’s Architecture Working Group, which concluded that Alibi should be used specifically for its ability to generalize to broader zero-shot contexts.
An Oversized Tokenizer?
While tokenizer size does impact model training, Bloom’s tokenizer size is consistent with other multilingual models such as PaLM, which also uses a 256k token vocabulary. Such sizes appear necessary to adequately represent all languages.
Architectural Revolutions in Mistral and LLaMA 2?
The SwiGlu activation function
First introduced in a 2020 Google paper, this activation function provides slight performance improvements in perplexity on an encoder-decoder architecture:
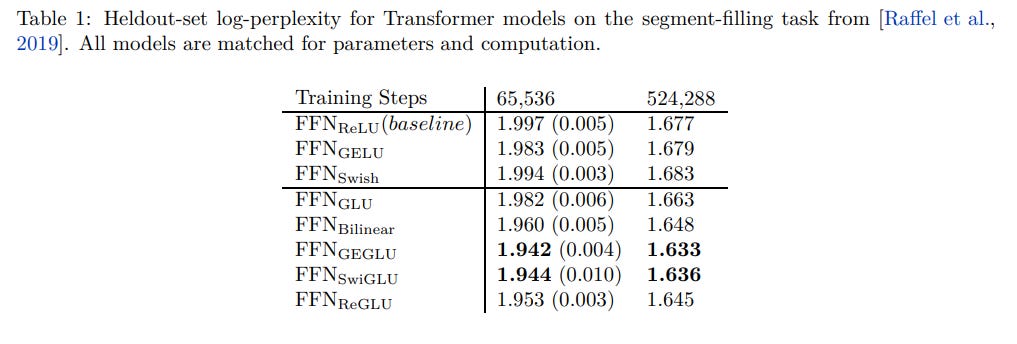
As well as on GLUE and SuperGLUE benchmarks, improving average scores from 84.20 to 84.36 and 73.95 to 74.56, respectively.
This activation function was also considered by Bloom’s Architecture Working Group, which ultimately reversed its initial decision and recommended SwiGLU for future models due to its slight advantage:
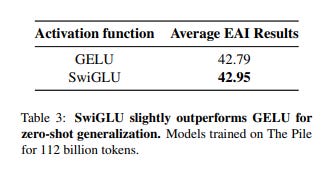
Root Mean Square Layer Normalization (RMSNorm)
The RMSNorm paper, published in 2019, demonstrates that this new normalization method provides significant computational speed gains while maintaining comparable performance to the traditional LayerNorm when applied to RNNs.
“Extensive experiments on several tasks using diverse network architectures show that RMSNorm achieves comparable performance against LayerNorm but reduces the running time by 7%∼64% on different models.”
Grouped Query Attention (GQA)
This technique, highlighted by the Mistral models and LLaMA 2 34B and 70B, originates from a 2020 Google Research paper. It demonstrates the ability to reduce the number of query matrices by sharing them across multiple attention heads, with little to no loss in performance, while reducing parameters and improving computational efficiency.
In this paper, they notably incorporate this mechanism by merging the queries of a pre-trained T5 model and continuing its pre-training. In practice, this approach can be applied to any transformer architecture.
However, it is true that this reduction in parameters allowed Mistral to increase the intermediate sizes of its feedforward layers compared to LLaMA 2, thus allowing a better allocation of computational resources.
A matter of training?
Bloom: A Largely Under-Trained Model, Even in Its 7B Version.
Optimizer and Data:
| name | optimizer | scheduler | warmup tokens | sequence_length/context | num_steps | batch_size | num_tokens_seen | num_english_tokens_seen |
|---|---|---|---|---|---|---|---|---|
| Bloom-7b | Adam | cosine | 375M | 2048 | 325k | 512 | 341B | 102B |
| Falcon-7b | AdamW | cosine | 30B | 2048 | 317k | 2 304 | 1 500B | ~1 455B |
| Llama2-7b | AdamW | cosine | ~8B | 4096 | 500k | 976 | 2 000B | ~1 800B |
| Mistral-7b | ? | ? | ? | nan | ? | ? | ? | ? |
While Bloom uses the Adam optimizer provided by the DeepSpeed Megatron library (as AdamW remains unavailable to this day), it would be misleading to attribute performance gaps to this choice. All of these models, except for Mistral (for which no information is available on this aspect), employ similar optimizers with comparable strategies, including warm-up and cosine scheduling.
The most notable difference in this table is the variation in the number of tokens processed during model training, which strongly correlates with their performance rankings.
Bloom-7B is trained on 5 to 6 times fewer tokens than its competitors, and even 15 to 18 times fewer English tokens - the language most commonly used in model evaluation today.
Chinchillas Laws, a strategic turning point.
Between Bloom’s release and the arrival of its successors, a DeepMind paper introduced a paradigm shift in the race for model size: the famous Chinchilla Laws, which suggests that most models at the time were undertrained.
What they say and don’t say
The Chinchilla laws show that there are optimal triplets of computational budget, model size, and training dataset size, where one parameter is determined by the other two.
If we start with a “computationally optimal” model (one of these optimal triplets) and decide to continue training with new data-fixing the model size while increasing the computational budget and the dataset size-the laws suggest that a larger model should have been used initially for better perplexity.
In essence, the Chinchilla laws do not imply that the model cannot improve with continued training; rather, they indicate that it is no longer the most efficient solution given the available computational budget.
The rule derived from the Chinchilla Laws is often summarized as: “You need 20 text tokens per model parameter”. While this is true for certain types of datasets, it raises questions about its applicability to more complex, simpler, or multilingual datasets. In addition, this rule applies specifically to “computationally optimal” models.
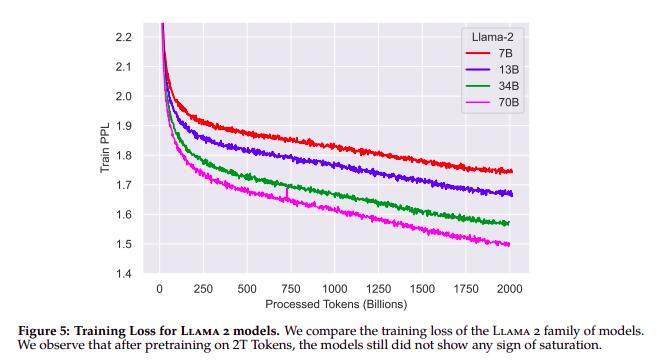
LLaMA 2’s training curves illustrate this concept well: for a 7B parameter model, the “compute-optimal” triplet corresponds to 7×20=140 billion tokens. However, the perplexity curves show that the 7B model continues to improve beyond this limit, converging to lower perplexity levels. Even after training on 2000 billion tokens, the model has not yet reached saturation.
Conclusion 🎯
I hope you’ve enjoyed this article and that it has provided additional insight into the differences and similarities between the Bloom model and its successors. Finally, I hope it underscores my belief in the power of open source, open data, and open science initiatives to create competitive models that can rival those of the major AI players.